





Tesla A100发布: 英伟达GPU架构如何演进?
关于NVLink,它于2016年首次与PascalP100 GPU一起推出,是NVIDIA专有的高带宽互连,旨在允许多达16个GPU相互连接以作为单个集群运行,应对更大的工作负载。对于Volta,NVIDIA对NVLink进行了较小的修订,将数据传输率提高了25%。同时,对于A100和NVLink3,这次是NVIDIA在进行更大的升级,使通过NVLink可用的总带宽增加了一倍。

总而言之,与NVLink 2相比,NVLink 3有两个重大变化,既可以提供更大的带宽,又可以提供更多的拓扑。
首先,NVIDIA有效地将NVLink的信号速率提高了一倍,从NVLink 2的25.78Gbps提高到NVLink 3的50Gbps。这使NVLink与其他互连技术保持同步,其中许多技术都类似地升级为更快的信号。另一个重大变化是,鉴于信号速率提高了一倍,NVIDIA还将单个NVLink中的信号对/通道数量减少了一半,一个NVLink内可用的带宽数量保持不变,速度分别为上行每秒25GB和下行每秒25GB(或通常每秒50GB/秒),但可以使用一半的通道来完成。
NVIDIA A100在软件也做了些优化,包括50 多个加速、仿真和AI CUDA-X库,CUDA 11,AI服务器框架 NVIDIA Jarvis,应用框架NVIDIA Merlin和NVIDIA HPC SDK。
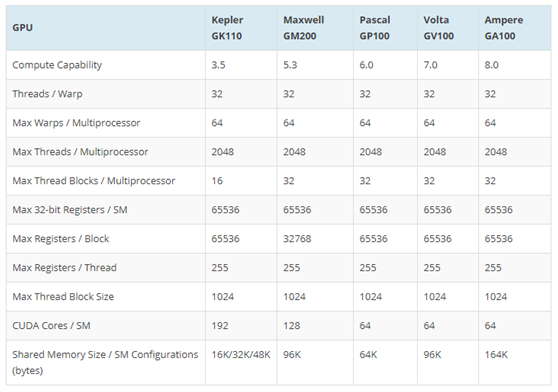
NVIDIA A100基于7nm Ampere GA100 GPU,具有6912 CUDA内核和432 Tensor Core,540亿个晶体管数,108个流式多处理器。采用第三代NVLINK,GPU和服务器双向带宽为4.8 TB/s,GPU间的互连速度为600 GB/s。另外,Tesla A100在5120条内存总线上的HBM2内存可达40GB。

从单一的Mezz Modular卡到全长PCIe 4.0图形卡,NVIDIA Ampere GA100 GPU提供尺寸不等的各种方案。GPU还具有多种配置,但NVIDIA今天重点介绍的是Tesla A100,它用于DGX A100和HGX A100系统。
关于NVIDIA Ampere GA100 GPU架构和规格,NVIDIA的Ampere GA100 GPU绝对是一个庞然大物。尺寸为826mm2,比Volta GV100 GPU的815mm2还要大。鉴于管芯尺寸和晶体管数量,Ampere GA100 GPU是单手构建的最密集的GPU。
Tesla A100 SMX模块具有带有6个HBM2堆栈的GA100 GPU。相比Tesla V100(Volta),SMX模块发生了变化,孔与上一代不对齐。推测,这可能是我们正在寻找的SMX Gen 4模块。该模具似乎比GV100稍大,估计为820-840 mm 2。GA100 Ampere有望作为数据中心GPU推出,专注于面向计算的Tesla系列。

NVIDIA也发布了 DGX A100系统,该系统由8个GPU A100通过NVLink互连。NVIDIA深度学习工作站,即DGX系统,经历了几次迭代。最早的系统采用Pascal GP100 GPU,随后推出了4款基于Volta架构的系统,规格包含4到16个Tesla V100处理器。

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-6.18立即报名>> 【在线会议】英飞凌OBC解决方案——解锁未来的钥匙
-
精彩回顾立即查看>> 【在线研讨会】普源精电--激光原理应用与测试解决方案
-
精彩回顾立即查看>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
精彩回顾立即查看>> 【在线会议】汽车检测的最佳选择看这里
-
精彩回顾立即查看>> 2024工程师系列—工业电子技术在线会议
推荐专题
中国人工智能产业大会“AI+智能硬件论坛”")



- 1 最强国产X86 CPU曝光:128核,512线程,性能直追intel/AMD
- 2 微星泰坦16 AI 2025评测:顶级性能 轻薄本续航
- 3 联想开天N8 Pro笔记本评测:移动版兆芯KX-7000效率甚至优于Intel/AMD
- 4 AMD RX 9070 GRE首发评测
- 5 技嘉B850M AORUS PRO WIFI7电竞雕主板评测
- 6 技嘉RTX 5060小雕首发评测:超越RTX 4060 Ti!2K也有一战之力
- 7 技嘉RTX 5070 Ti超级雕评测
- 8 酷睿Ultra 9 275 HX与i9-14900HX深度对比!联想拯救者Y9000P 2025至尊版评测
- 9 影驰RTX 5060 Ti金属大师白金版16GB MAX OC评测
- 10 智能硬件C端承压,科大讯飞的困局与隐忧



发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论